
Most B2B scoring models break inside of six months. The model logic usually isn’t the problem — the business changed, the signals decayed, and no one recalibrated. This guide is a vendor-neutral operating framework for building a scoring model that survives contact with sales, with CRM-native implementation paths and a recalibration cadence the reviewers of vendor blogs skip.
We’ll cover when scoring is the wrong project to start, how to choose between rules-based, predictive, and hybrid models, and the maintenance loop that keeps a model honest past quarter one.
Do You Actually Need Lead Scoring?
Lead scoring solves a capacity problem, not a lead generation problem. If your SDRs can call every inbound lead this week and still have time to prospect, you don’t need a scoring model — you need more leads at the top of the funnel. A scoring project will swallow three months of RevOps time and return nothing, because there was no queue to prioritize.
Scoring earns its keep when inbound volume exceeds sales capacity to contact everyone. That’s the trigger. Before you start, answer three questions:
- Can sales work every lead? If yes, stop. Fix lead gen first.
- Are reps already making triage calls by gut? That’s the queue scoring will replace.
- Do MQLs and SQLs have a shared, written definition? If no, scoring will arrive before the argument it’s supposed to settle.
Only projects that clear these three belong in a sprint plan.
What B2B Lead Scoring Is in 2026
B2B lead scoring is the system that ranks inbound and outbound leads by likelihood to convert, so sales works the highest-probability accounts first. Modern B2B scoring combines firmographic and demographic fit (does this lead look like a customer?) with behavioral intent (is this lead buying now?), either through rules, machine learning, or a hybrid of both.
That’s the whole definition. Skip the 101; the rest of this piece is about how to build a model that doesn’t decay before your next QBR.
Rules-Based vs Predictive vs Hybrid: How to Choose
The rules-based vs predictive debate is usually framed as “AI is the future.” It isn’t that simple. Classical machine learning is cheap and fast to build — a competent team can stand up a working model on Amazon SageMaker in a couple of days. The bottleneck isn’t the algorithm; it’s the labeled data you have to feed it.
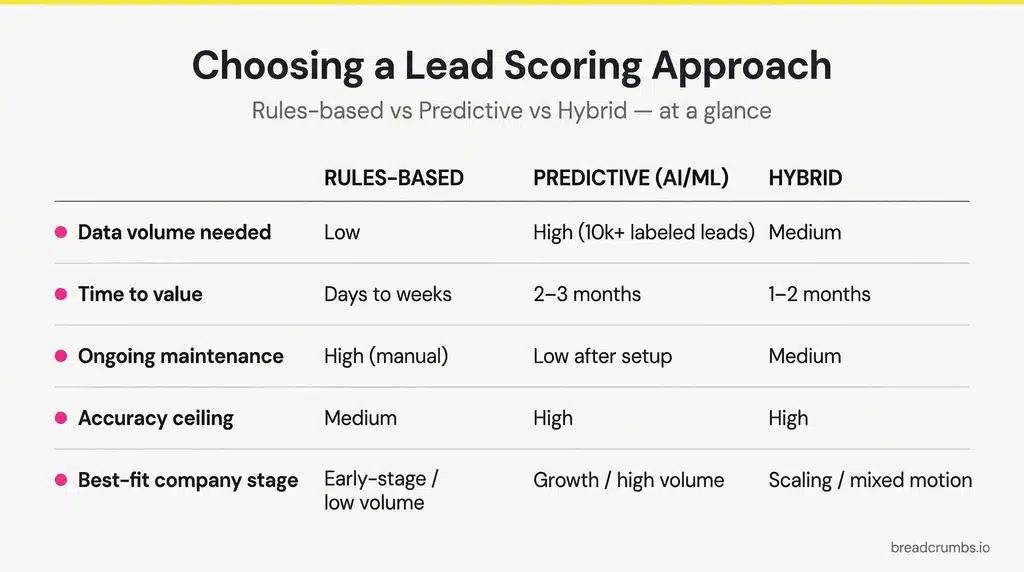
Here’s the decision matrix.
| Dimension | Rules-Based | Predictive (ML) | Hybrid |
|---|---|---|---|
| Time to first model | Days (manual) | Days to weeks (given data) | Weeks |
| Data minimum | None | HubSpot AI scoring: 25 converted + 25 non-converted contacts. Microsoft Dynamics: 40 qualified + 40 disqualified leads | Same as predictive for the ML layer |
| Ongoing maintenance | Manual rule edits | Retraining on new data | Both |
| Accuracy ceiling | Capped by what RevOps can hand-encode | Higher if labeled history is clean | Highest when fit is rules-based and behavior is ML-driven |
| Best-fit stage | New scoring programs, low-volume funnels, cold-start | Businesses with clean won/lost history and a stable ICP | Mature B2B SaaS with real data and multiple sales motions |
| Fails when | Volume grows past manual review | Labeled data is sparse, noisy, or non-stationary | Sales and marketing don’t co-own the rule layer |
Sources: HubSpot lead scoring documentation; Microsoft Dynamics 365 predictive lead scoring.
When predictive actually wins
A 2025 paper in Frontiers in Artificial Intelligence trained a gradient-boosting classifier on four years of CRM lead data (January 2020 – April 2024) and found it outperformed the company’s existing traditional model. 6sense’s Ceros case study reports 450 new opportunities in six months and a 72% lift in meeting-to-SQL rate after switching from manual target-account lists to intent-led prioritization.
Predictive wins when timing matters more than triage and there’s enough labeled history to train on.
When predictive is the wrong call
The most common overhype is pitching ML into a cold start. HubSpot and Microsoft Dynamics both refuse to generate a predictive model below their labeled-data minimums — that’s a product-level constraint, not a philosophical one. If you’re under 50 clean conversions and 50 clean non-conversions, rules-based is the correct starting point, not a fallback.
Predictive also underperforms when the ICP is non-stationary. More on that in the recalibration section.
The honest recommendation
Hybrid is the default for mature B2B SaaS. Use rules for firmographic/demographic fit (you already know what your ICP looks like — encode it). Use ML for behavioral scoring, where correlations are non-obvious and timing matters. MadKudu’s product ships exactly this split: separate Customer Fit, Likelihood to Buy, and a combined Lead Grade.
The Four Inputs Every B2B Scoring Model Needs
Every working lead scoring model pulls from four signal buckets: firmographic fit, demographic fit, behavioral intent, and negative signals. Miss one and the model is asymmetric — usually too optimistic about poor-fit accounts or too punishing toward good-fit accounts in a quiet week. Treat the four as the minimum spec, not a menu.
Firmographic fit (ICP signals)
Company-level attributes: industry, employee count, revenue, tech stack, region. These change slowly, so their half-life is long. A lead that’s firmographically ideal today will still be firmographically ideal next quarter unless you change your ICP. Pull from enrichment (Clearbit, Apollo, ZoomInfo) and from your own CRM.
Demographic fit (persona signals)
Person-level attributes: job title, seniority, function, department. Weight these the way sales actually weights them — a director in the buying committee is not worth the same as an IC who happened to fill out a form. If sales only closes deals involving a VP or above, make sure the model reflects that.
Behavioral intent (engagement signals)
Actions: pricing page visits, demo requests, content downloads, email engagement, product usage for PLG. Behavioral scores are time-sensitive. MadKudu recomputes behavioral scores several times per day, because a pricing page visit today and one six months ago are not the same signal. Assume a short half-life here.
Negative signals (disqualifiers)
The inputs most teams skip. Subtract points for anything that makes a lead worse, not just everything that makes a lead better. Reliable disqualifiers:
- Students, job seekers, competitors, internal employees
- Out-of-region or out-of-market records
- Unsubscribed contacts (HubSpot’s own example subtracts points when a contact unsubscribes)
- Repeated visits to the careers page (a flag Adobe’s Marketo team calls out in their 2025 scoring webinar — often job-seekers, not buyers)
- Complete opt-outs from all comms (Adobe recommends a full score reset)
A model without negative scoring will eventually recommend a competitor’s employee who keeps visiting your pricing page. That’s embarrassing.
Building Your First Scoring Model (Step-by-Step)
Building a working scoring model is six concrete steps: validate what actually predicts close rate, pick a point scale, assign points by signal bucket, set a sample allocation, define MQL and SQL thresholds, and backtest on historical data before going live. Skip step one and the rest is guesswork with a point total attached.
- Validate what actually predicts close rate. Before you assign a single point, run an analysis on closed-won vs closed-lost from the last 12–24 months. What firmographic, demographic, and behavioral attributes show up more often in closed-won? This is where ML is genuinely useful even if your final model is rules-based — use a regression or a gradient-boosted classifier to rank attribute importance. The inputs your gut says matter and the inputs that actually correlate with revenue are usually different lists.
- Pick a point scale. 0–100 is the most common and pairs well with the MadKudu-style grade bands (90–100 = A, 75–89 = B, 50–74 = C). Keep it simple — a 0–1000 scale signals precision you don’t have.
- Assign points by bucket. Split your 100 points roughly 60/40 between fit and behavior for a straight sales-led motion, or 50/50 for PLG motions where product signals carry more weight. Inside fit, reserve negative-scoring headroom (typically −30 to −50 points for hard disqualifiers).
- Set a sample point allocation. Worked example, SaaS with a sales-led motion:
- VP/C-level title: +15
- Director title: +10
- Target industry (SaaS, fintech): +15
- Company size 50–500: +15
- Pricing page visit (last 7 days): +10
- Demo request: +25
- Free trial signup: +15
- Competitor employee / student / job seeker: −40
- Unsubscribed: −25
- Define MQL and SQL thresholds. Pick a score that triggers the handoff — more on the method below. Don’t copy an “industry average” — it’s noise.
- Test on historical data before going live. Score last quarter’s leads against the new model. Do the highest-scoring leads actually correspond to closed-won? If not, the weights are wrong, and pushing to production will just create a loud bad model. Iterate until the rank correlation holds.
Setting Score Thresholds and the MQL→SQL Handoff
Thresholds aren’t industry benchmarks — they’re the score where sales starts working a lead. Set the threshold by running the new model against historical data and finding the score above which conversion rates jump materially. That’s your MQL line.
The SQL threshold is a separate question: it’s not a higher score, it’s a different qualification event — typically sales-accepted after an outreach or discovery call. Don’t let the scoring model make the SQL decision. That’s the rep’s job.
Sales must co-build, not receive
The most common reason scoring projects fail isn’t bad logic. It’s that sales doesn’t trust the score, so reps keep working whoever they were working before. Marketing hands down a model, the score column in the CRM lights up, and pipeline priorities don’t change at all.
The fix is structural: sales co-builds the model, from day one. Not “aligns with sales” as a soft bromide. A working co-build looks like:
- Sales picks the weights. A kickoff workshop where reps assign points to every attribute alongside RevOps. If sales says demo requests are worth more than webinar attendance, demo requests get more points.
- Sales approves the disqualifiers. The negative-signal list is ratified by the people actually making the calls.
- A named sales co-owner attends every recalibration review. When the model changes, the sales lead signs off before it ships.
- MQL rejections route back. Every rejected MQL includes a reason code, and the reason codes feed the next recalibration.
When the scoring model is something sales built, sales works it. When it’s something marketing imposed, sales ignores it. That’s been true across every lead scoring project we’ve seen fail or succeed.
Score Decay and Recalibration: The Section No One Writes
Models break because the world moves. There are two separate decay problems to maintain against, and almost every vendor article covers only the first: signal decay (behavioral inputs lose meaning as they age) and strategy-change decay (ICP shifts invalidate the model’s historical baseline). Handle both, or the model drifts into noise inside a year.
Signal decay: behavioral inputs have a short half-life
Behavioral signals get stale fast. A pricing page visit two days ago is meaningful. A pricing page visit six months ago is noise. If those two events add the same points to the score, the model is lying to sales.
HubSpot handles this with timed score decay at 1, 3, 6, or 12 months. Their own example: a 10-point form-fill rule with 50% monthly decay contributes 5 points after one month and 0 points 30 days after that. Adobe Marketo recommends a parallel mechanic — subtract points each month a contact doesn’t engage with email or web content.
As a default rule of thumb:
- Firmographic and demographic fit: long half-life. Don’t decay these automatically; refresh them through enrichment runs.
- Behavioral intent: short half-life. Apply timed decay (1–3 months for most inbound signals) or recompute from a rolling window.
Strategy-change decay: the hidden trap
The second decay is the one that torches predictive models. ML scoring is a backward-looking model — it learns what drove close rate in the past. When the business changes what it’s selling, who it’s selling to, or where it’s selling, the historical correlations don’t apply to the new target anymore. Predictive scores on new-strategy leads will be systematically wrong, usually in the direction of the old ICP.
Common triggers that invalidate an ML model, regardless of how clean the signal decay is:
- Moving up-market or down-market (new company-size band in the ICP)
- Launching a new product with a different buyer persona
- Entering a new geography or vertical
- Repricing (new price point shifts the win-rate curve)
- Changing the sales motion (sales-led → PLG, or the reverse)
If the business changed the strategy, the model didn’t. Recalibrate before the strategy ships, not after pipeline craters.
Recalibration cadence
Adobe’s 2025 Marketo webinar recommends treating the scoring model as a living document reviewed monthly or quarterly, and at minimum every six months. Quarterly is the operating default for an established model. Move faster when:
- MQL-to-SQL conversion drops for two consecutive weeks
- Sales rejection reasons cluster around the same issue
- The business announces a new market, region, or product
- Enrichment or product-usage data changes what the model can see
The recalibration isn’t complicated: pull the last quarter’s leads, re-score them, check whether the rank order still predicts close rate, and adjust weights where it doesn’t. A two-person workshop — RevOps and sales — finishes in an afternoon.
Real-World Examples
Two named SaaS examples, one from each end of the rules-based/predictive spectrum. Thinkific shows a hybrid fit-plus-engagement model delivering an MQL→Opportunity lift at SaaS scale. Ceros shows what predictive account prioritization can unlock when data maturity and intent signals align. Both are concrete — no anonymous “Company X” stand-ins.
Thinkific: hybrid fit + engagement, 2x MQL→Opp in three months
Thinkific, an online course platform, unified data from HubSpot, Salesforce, website behavior, and in-product activity into a single acquisition scoring model. Fit inputs: job title and industry. Engagement inputs: website visits, page views, and time spent on pages. MQL-to-opportunity rate doubled in three months.
What to learn from it: cross-system data and a simple fit+engagement split is often enough. Thinkific didn’t start with ML. They started with a rules-based hybrid model that respected both who the lead was and what the lead did.
Ceros: predictive account prioritization, +72% to +118% across the funnel
Ceros, a design platform, had SDRs juggling 300–400 target accounts each without a prioritization system. After adopting 6sense’s intent platform, reps focused on the top 10–20 accounts in the Decision and Purchase stages daily. The results over six months: 450 new opportunities, +72% meeting-to-SQL rate, +22% average deal size, +109% win rate, +118% opportunities.
What to learn from it: when timing and hidden research behavior matter, and there’s enough data maturity to support it, predictive prioritization outperforms manual target-account lists by a lot. This is the shape of ABM motions where predictive earns its keep.
Common B2B Lead Scoring Mistakes
Five failure modes we see in practice — each one common enough that every scoring project we’ve audited has hit at least two. They’re structural, not exotic: bad data inputs, missing disqualifiers, over-weighted intent events, stale behavioral signals, and a sales team that never co-built the model. Fix these five and most scoring projects stop failing.
- Scoring on form fills that don’t actually correlate with revenue. A lead fills out five forms and scores high — but five-form leads close at the same rate as two-form leads. The fix is the pre-model analysis in step 1 of the build process: validate which inputs predict close rate before weighting them. Guessing is expensive.
- No negative scoring. The model only adds points, never subtracts. Result: competitors, job seekers, and internal employees stack up near the top of the queue. Every mature model has disqualifier rules; most first drafts don’t.
- Over-weighting demo requests. A demo request looks like peak intent, so teams weight it at 40+ points. Then every lead who wanted a five-minute tour to kill an hour gets routed to a rep. Demo requests are a strong signal, but they should live alongside fit — a demo from a fit-score-zero lead is worth almost nothing.
- No decay on behavioral signals. A pricing page visit in March 2025 should not be worth the same as one in April 2026. If you can’t set decay in your scoring tool, recompute from a rolling window.
- Building without sales. RevOps ships a model, sales ignores it. See the co-build section above — this is the single most common cause of scoring project failure, and it’s organizational, not technical.
For a deeper list, read our lead scoring best practices piece.
Tools and Implementation Path
Start with your CRM. Scoring has consolidated into a feature of the CRM layer over the last three years. Dedicated scoring startups have been acquired or merged, and CRM-native scoring has a structural advantage — the data already lives in the CRM, so there’s no integration tax.
CRM-native first
- HubSpot. HubSpot’s native scoring is genuinely good — manual rules, event-level decay, and AI-assisted scoring once you cross the labeled-data threshold (25 converted + 25 non-converted contacts). For most B2B SaaS companies on HubSpot, the native tool is enough.
- Salesforce. Salesforce ships scoring natively across Sales Cloud and Marketing Cloud, with Einstein Lead Scoring as the predictive layer. Strong fit for larger orgs already on the Salesforce stack.
- Marketo. Marketo’s scoring is powerful for enterprise marketing teams, particularly when paired with Salesforce on the CRM side.
- ActiveCampaign. For SMB and mid-market teams, ActiveCampaign’s lead scoring is a credible CRM-native path.
When a dedicated scoring tool still makes sense
Two cases justify a dedicated tool.
- Product-led growth. If product-usage signals drive a meaningful share of your score and your CRM can’t natively pull them, a dedicated scoring layer (MadKudu, Pocus, etc.) that unifies CRM and product data is the right call.
- Multi-stack with no data warehouse. If your stack has a CRM, a marketing automation platform, a product analytics tool, and no warehouse unifying them, a dedicated scoring layer that sits on top can be the only way to get a single score.
Outside those two cases, the juice isn’t worth the squeeze. For a full implementation walkthrough on criteria that still hold up in 2026, read our deep dive.
Key Takeaways
- Scoring solves capacity problems, not lead gen problems. If sales can work every lead, don’t start.
- Hybrid is the default for mature B2B SaaS. Rules for fit, ML for behavior, sales-approved weights.
- ML is cheap; data is the bottleneck. Model quality is capped by input quality. Validate what actually predicts close rate before weighting anything.
- Sales must co-build. A model marketing hands down is a model sales ignores.
- Recalibrate against two decay types. Signal decay (behavioral inputs go stale) and strategy-change decay (ICP shifts invalidate historical correlations).
Once the framework is live, the next piece to build is the criteria list itself — which signals, weighted how, for your ICP. Our lead scoring criteria deep dive takes the framework here and turns it into a working point allocation you can adapt this quarter.